Automatic annotation, real-time sequence analysis &
protein structure prediction
Be confident in your sequences with our comprehensive DNA sequence editing tools.Edit and annotate your sequences then export your work into publishable images.
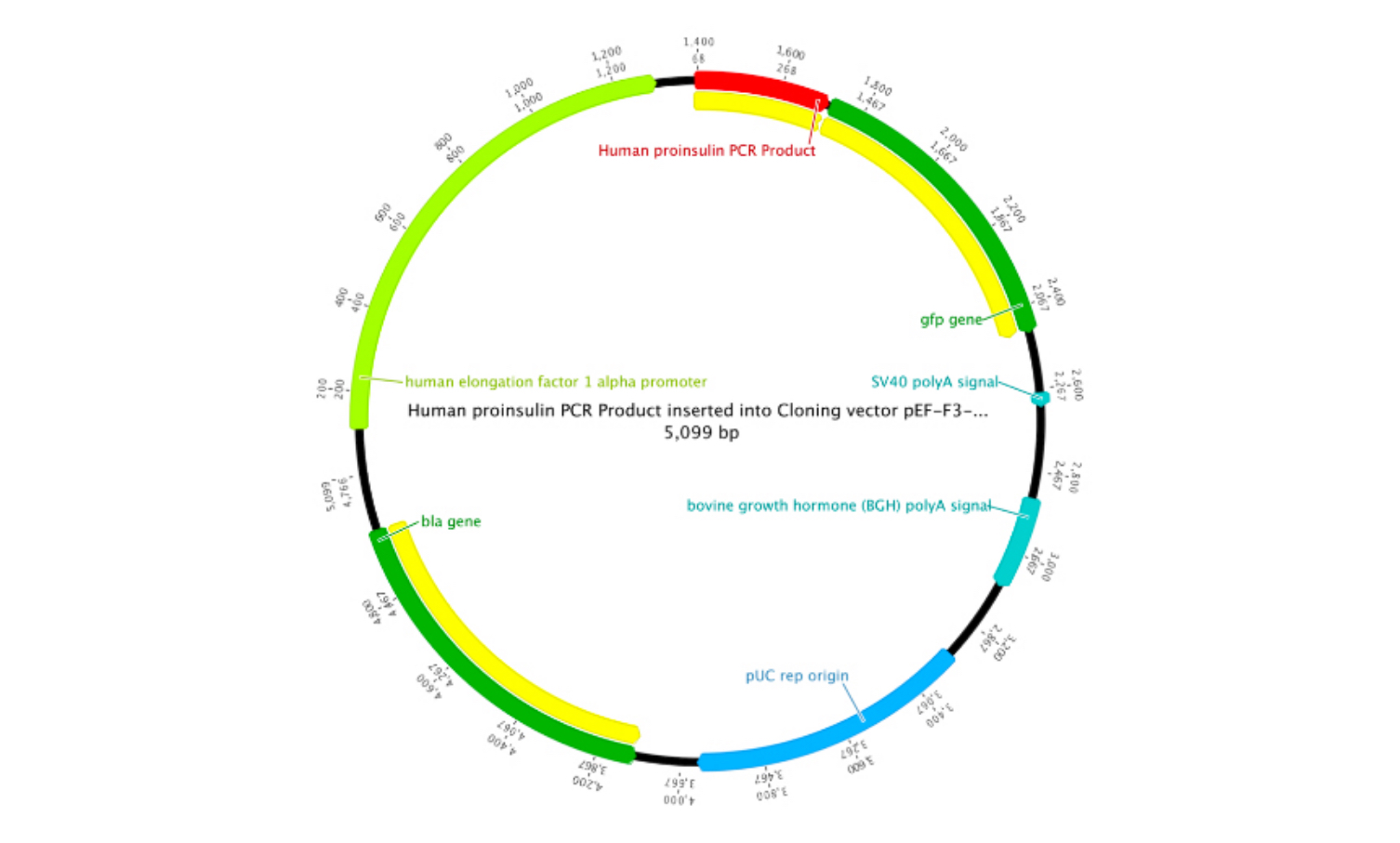
Discovery is easy with automatic annotations
NCBI의 패턴과 쿼리에 기반한 가상 유전자로써 ORF 주석을 포함하여 공개 또는 로컬 데이터베이스의 기존 패턴과 주석을 기반으로 새로운 게놈에 자동으로 주석을 달 수 있습니다.
- ORFs로 서열에 주석을 달거나 Glimmer로 유전자를 예측합니다.
- 시퀀스를 복사하고 붙여 넣어 모티프를 검색합니다.
- 유사성 기반 주석 (시퀀스의 대규모 데이터베이스)
- 서열 정렬을 이용하여 주석을 전송합니다.
- 포보스를 이용하여 탠덤 반복을 발견합니다.
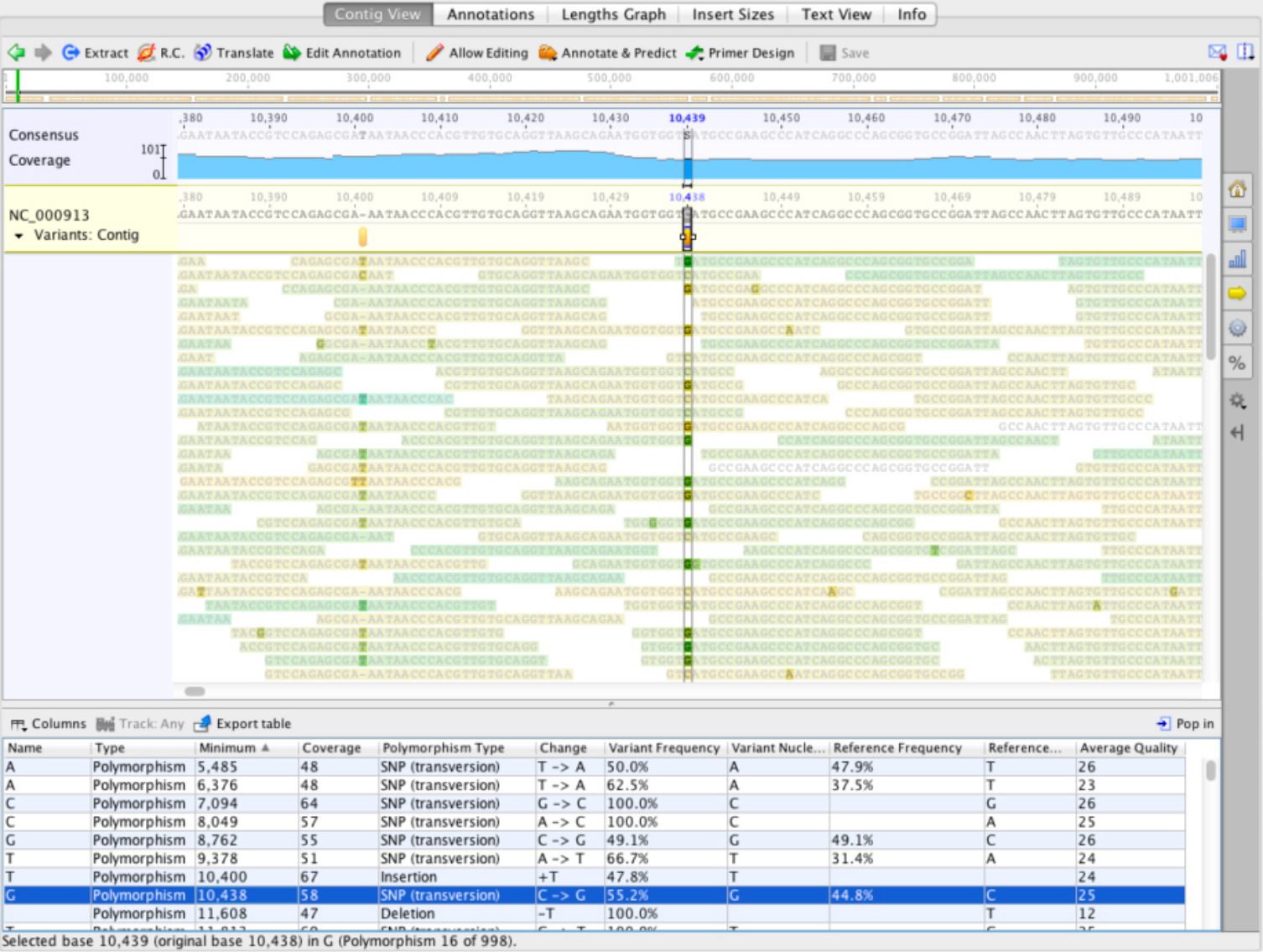
Powerful SNP detection and variant calling
브라우저에서 read들을 볼 수 있습니다. 시퀀스 뷰어에서 직접 불일치를 쉽게 식별, 검사 및 해결하거나 더 큰 컨티그 상에 있는 변이들의 주석을 빠르게 달 수 있습니다. 이 기능은 다음과 같이 구성되어 있습니다.
- 최소 임계값 이상의 불일치를 찾아서 read 오류를 검색합니다.
- 코딩 영역에서만 불일치를 찾습니다.
- 코돈의 첫 번째와 세 번째 위치만 다른 경우를 포함하여 단백질 번역에 대한 변이들의 효과를 확인합니다.
- SNP가 정확한지 확률을 계산합니다.
- 높은 가닥 편향을 가진 SNP를 제거합니다.
- 변이 정보들을 csv로 내보냅니다.
- 짧은 탠덤 반복(STRs)과 insertion 및 deletion(InDels)과 같은 짧은 구조적 변이들을 검색하고 주석을 답니다.
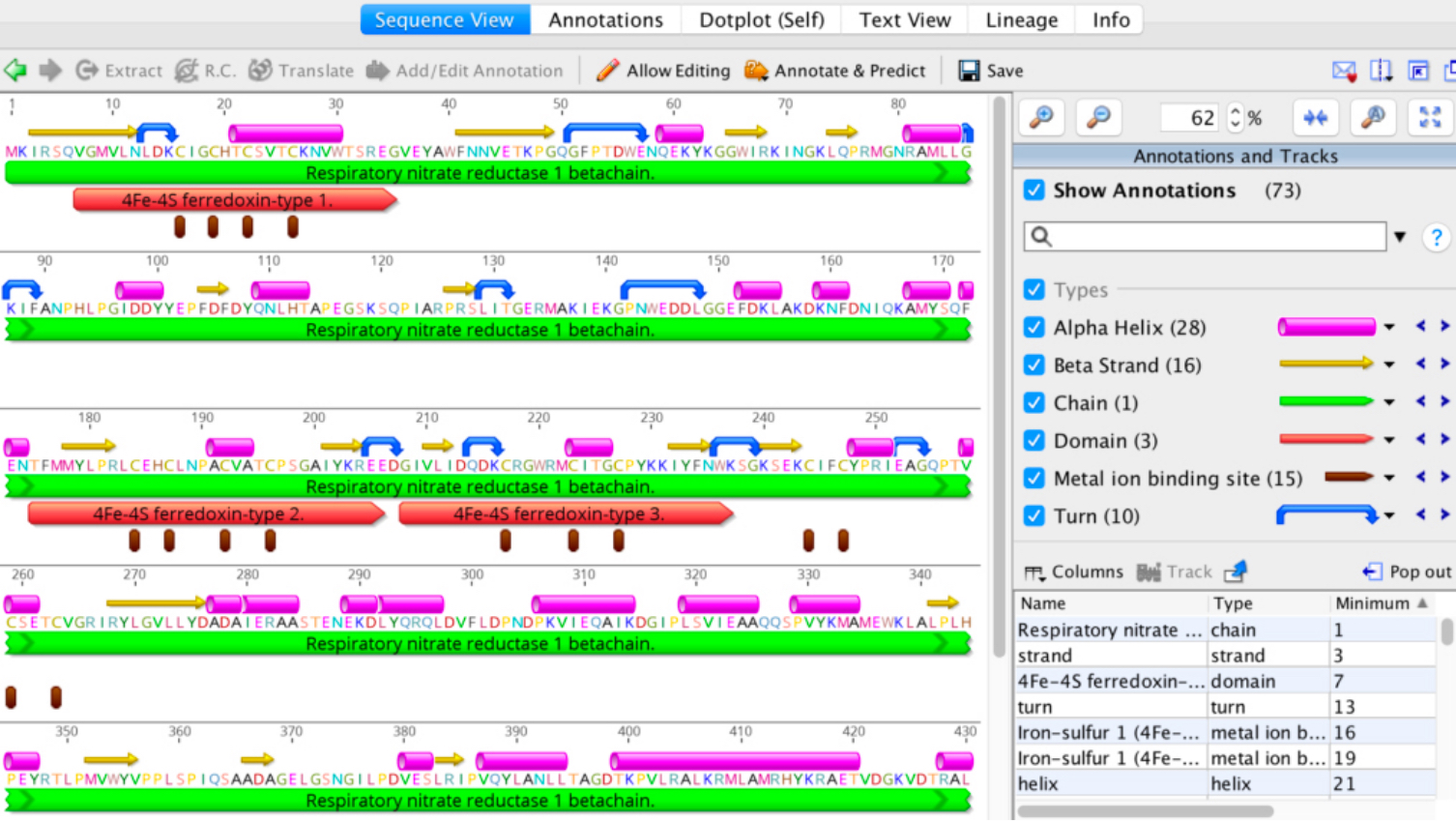
Real-time sequence prediction
몇 번의 클릭으로 다음과 같은 서열들을 확인할 수 있습니다.
- DNA translation: 뉴클레오티드 서열과 함께 번역하고 보완합니다. 6개 프레임을 한 번에 모두 번역하거나 어떤 프레임이든 관심 있는 주석이나 선택을 하여 번역하면 됩니다.
- Consensus Sequence: 최적의 기본 호출을 자동으로 선택하는 크로마토그램 데이터 상의 “consensus by quality”된 부분을 포함한 신원 확인 방식에 따라 공통 서열을 예측합니다.
- DNA sequences: ID, read 범위, 기본 빈도에 대한 수많은 통계, 잔류 빈도, CpG islands 등을 예측합니다.
- Protein sequences: 분자량, 등전점, 소수성, 막 횡단 영역, coiled coil 영역, 아미노산 전하 등을 예측합니다.